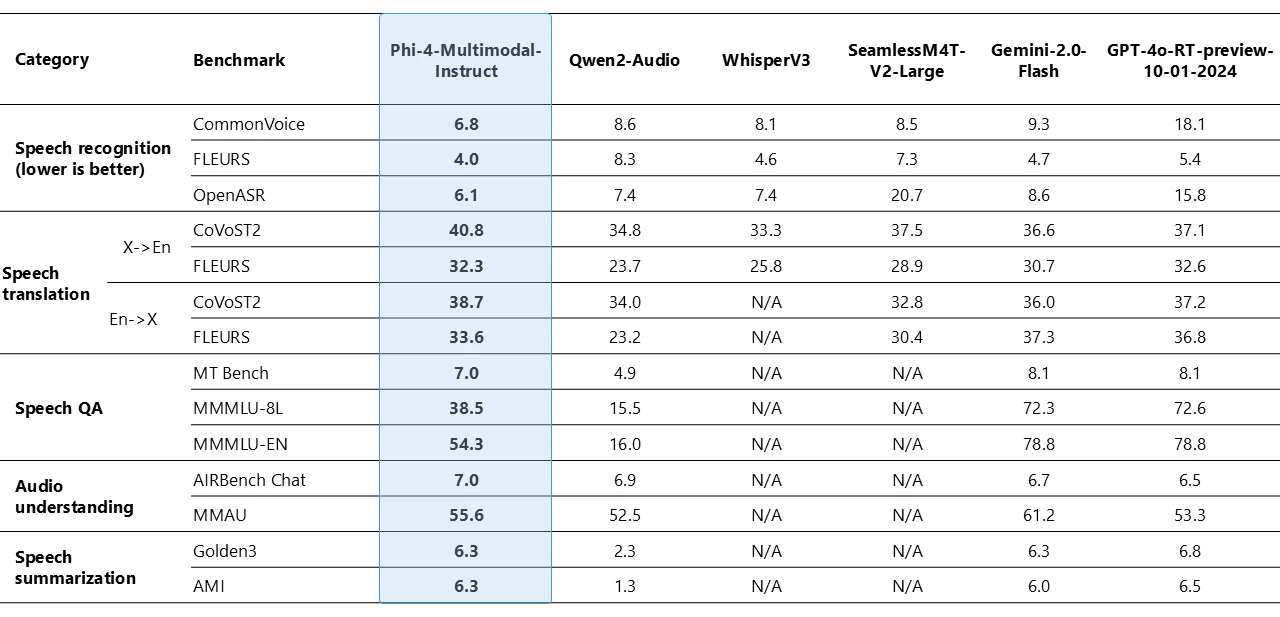
Think multimodal AI needs massive models? Think again!
Microsoft's Phi-4-multimodal is here to challenge that, packing speech, vision and language processing into a lean 5.6B parameters. What's the secret? A "mixture-of-LoRAs" architecture that allows it to handle different data types in parallel, creating a truly unified experience. This means you get a single model for text, audio and images, simplifying complex workflows and eliminating the need for separate, specialised models. Plus, it boasts a 128k token context window for deeper understanding.
For those use cases focused on text-only, the even smaller Phi-4-mini (3.8B) delivers surprising performance. It's proving that efficiency doesn't mean sacrificing capability, outperforming larger models in demanding tasks like reasoning, mathematical problem-solving, code generation, instruction following and function calling. This demonstrates a significant step towards more accessible and efficient AI.