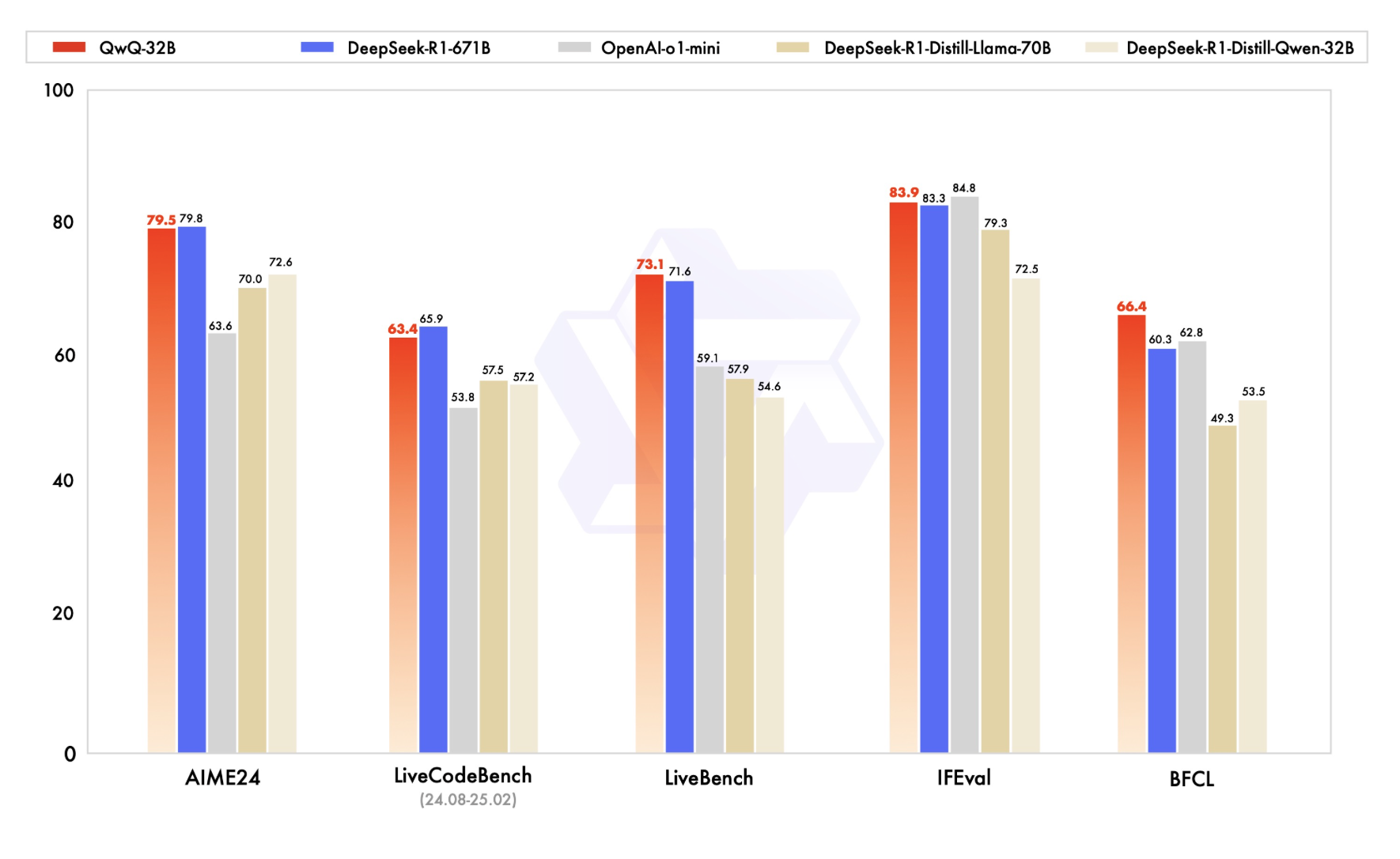
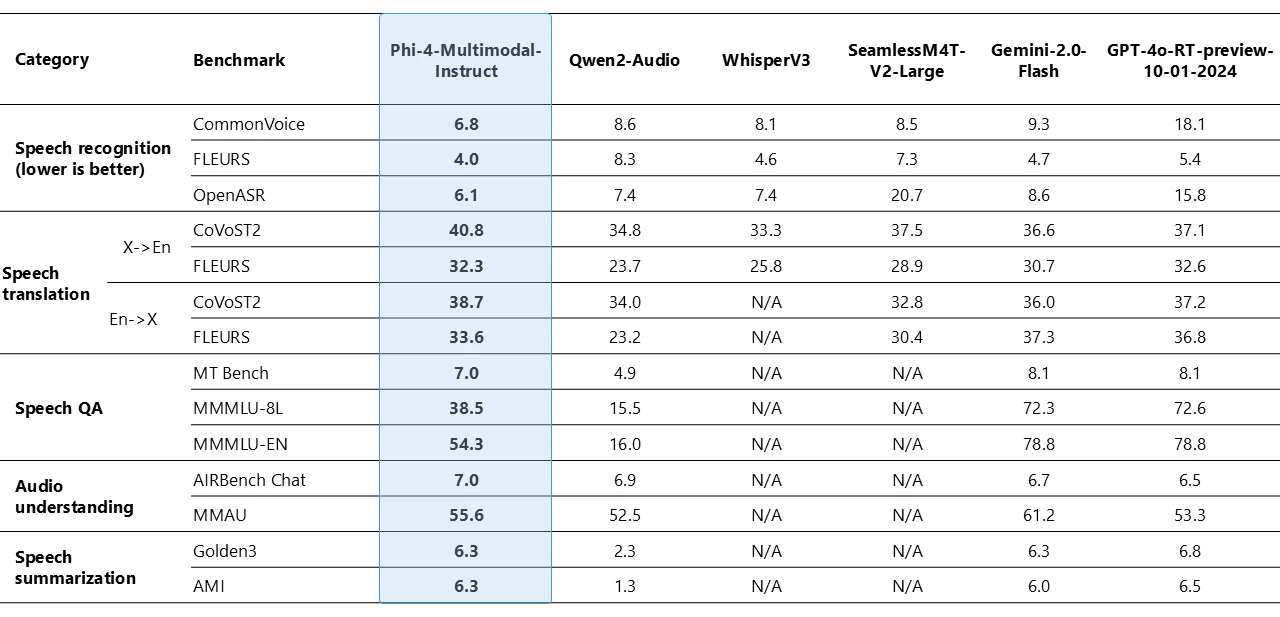
Rapidly Evolving Agentic Frameworks
The agentic framework ecosystem is rapidly evolving 🚀, with AutoGen, MetaGPT, LlamaIndex, LangGraph, CrewAI and most recently, smolagents. Over the past six months, I've experimented with each of these to varying degrees. While I've seen strong results with publicly hosted models from Anthropic and OpenAI, local Ollama integration 🛠️, particularly for tool-calling …
more ...