GLM-5.2 has generated significant interest since its release earlier this month. It combines strong published benchmark results with a 1M-token context window and open-weight availability under the MIT license. This has enabled hosted access and local quantisation options for high-memory systems.
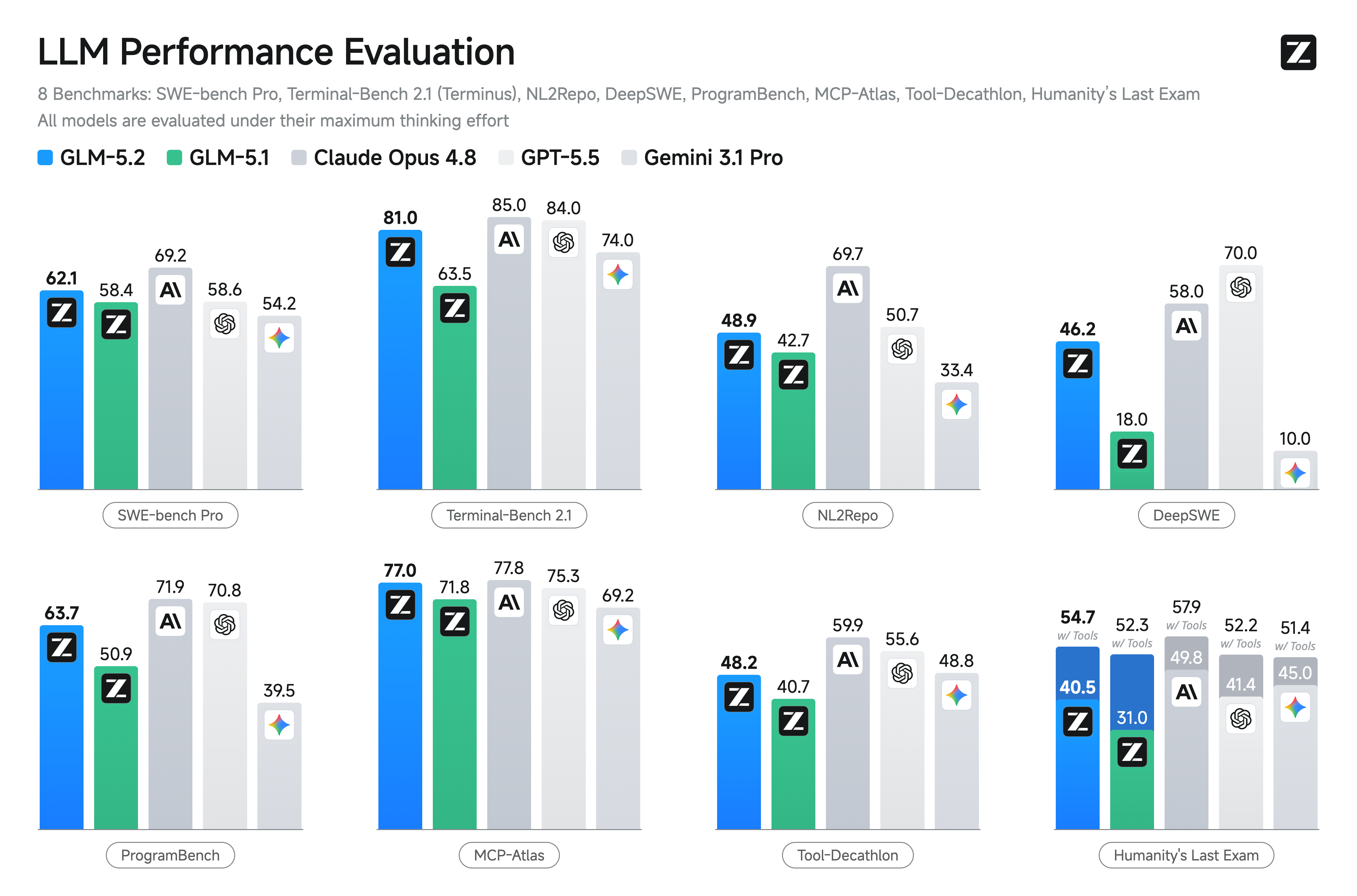
Z.ai's published benchmark card for GLM-5.2 reports impressive scores—including HLE 40.5, SWE-bench Pro 62.1, Terminal Bench 2.1 81.0, MCP-Atlas 77.0 and Tool-Decathlon 48.2. These results place it among the strongest models available today, today, in the upper tier of current frontier-class models.
Another reason the model stands out is pricing: Z.ai lists GLM-5.2 at $1.40 per million input tokens and $4.40 per million output tokens, which is materially lower than most premier models. Token cost and benchmarks, however, are not the only determinants of value outside controlled test cases.
Unsloth's local model guide shows why the community is excited about running it locally. The full model is listed at about 1.51TB, while the quantised variants range from 223GB for dynamic 1-bit, 245GB for dynamic 2-bit, 290–360GB for 3-bit, 372–475GB for 4-bit, 570GB for 5-bit and 810GB for 8-bit. Unsloth also reports an approximate top-1 MMLU accuracy of 76.2% for 1-bit and 82% for 2-bit, which supports the broader point that quantisation can preserve surprising levels of quality relative to the memory savings it unlocks.
However, local deployment is more nuanced than the raw file sizes suggest. The published model sizes do not by themselves prove that a given machine can run a given quantisation practically at a useful context length, because real-world usage also depends on operating-system overhead, KV cache requirements, and the serving stack. For instance, in one recent account, a user reported running the 4-bit quantised version of GLM-5.2 on a Mac Studio with 512 GB of RAM, resulting in 12 tokens per second output but only at 75k context window before running out of resources. The safest conclusion is that GLM-5.2 is locally deployable in high-memory configurations, especially in the mid-quantisation range, but that practical usability still depends on the available memory headroom and the workload.
For practical offline use cases, the model looks most compelling in agentic and asynchronous workflows. If your goal is high-volume coding, long-context analysis, or background automation, the combination of strong benchmark results, 1M-token support, and low token pricing makes GLM-5.2 attractive for a range of public and private use cases. If your local setup is more modest in memory, you'll probably be better off with Z.ai's mid-tier 'flash' models. The distilled GLM-4.7 Flash was my go-to model for several months. Hopefully we'll see a flash variant of GLM-5.2 later this year.